基于人工智能的植物藥創新研發平台
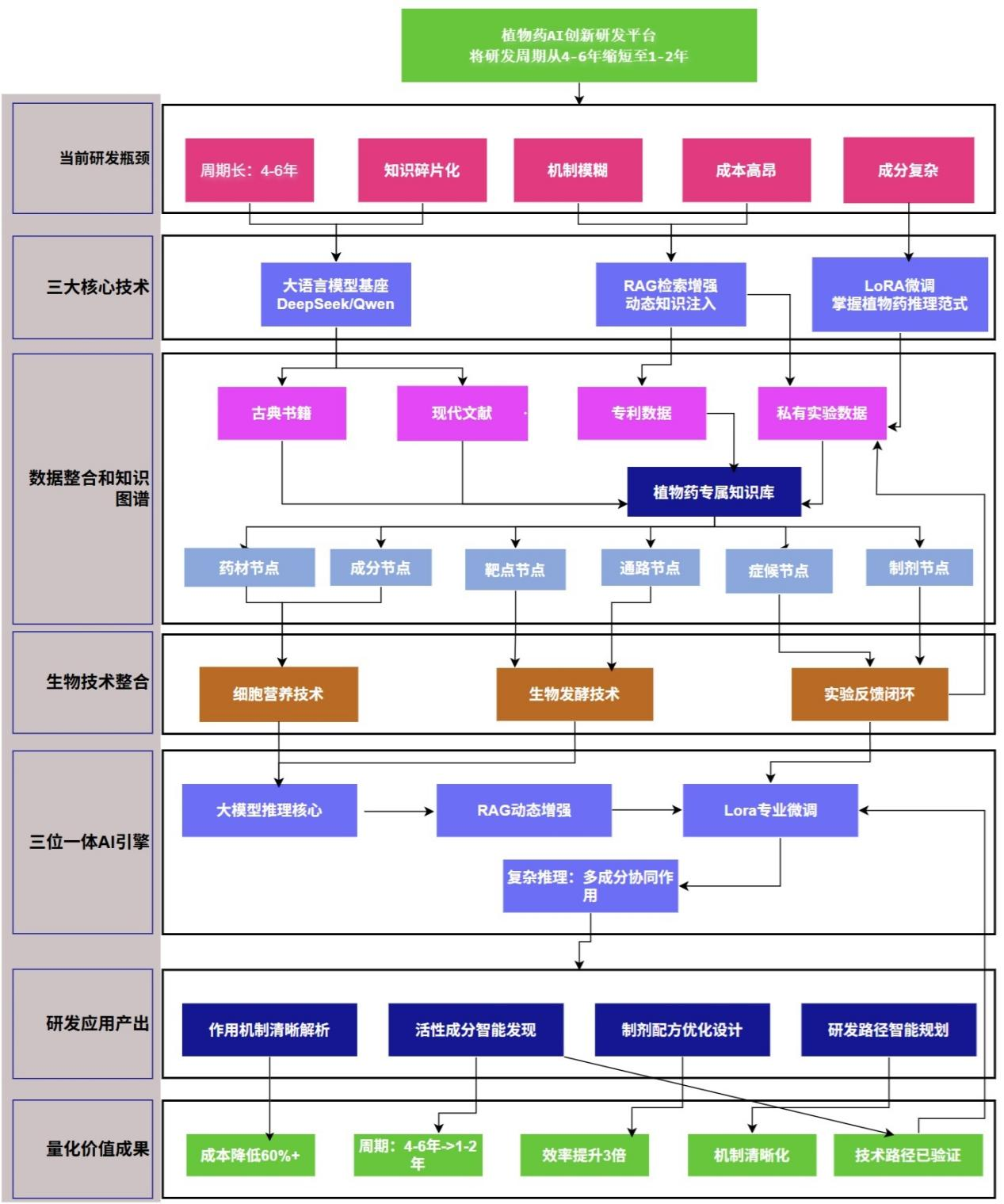
本項目是我們的AI研發團隊針對當前植物藥研發周期長、機制模糊、活性成分複雜及知識碎片化等核心瓶頸,研究和構建壹個融合大模型、檢索增強生成(RAG)與微調技術的專屬AI創新研發平台。通過系統性整合古籍典籍、現代文獻、專利及私有實驗數據,結合細胞營養技術和生物發酵技術,構建覆蓋“藥材–成分–靶點–通路–症候–制劑”全鏈條的植物藥專屬知識圖譜。在技術架構上,平台采用“大模型+RAG+LoRA微調”三位壹體模式:以DeepSeek/Qwen等LLM爲基座大模型,利用RAG和向量反饋技術動態注入最新領域知識以提升准確性,並通過專家標注的指令數據集進行LoRA微調,使模型掌握植物藥特有的多成分協同作用等複雜推理範式。目前已經初步證明了技術路線的可行性,有望將植物藥研發周期從傳統的4-6年縮短至1-2年,顯著降低研發成本並提升效率。
改進RAG+向量反饋推理引擎
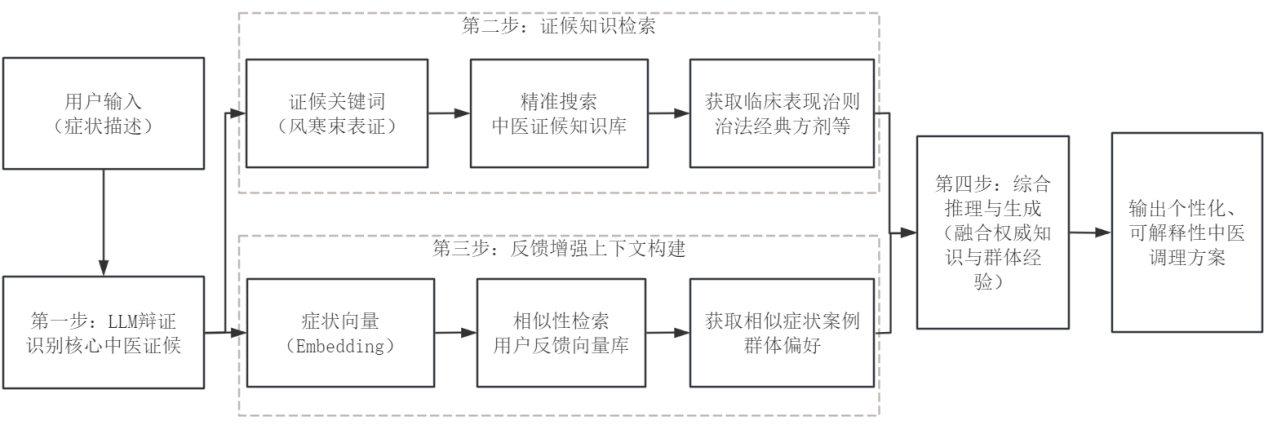
引擎層是壹個基于FastAPI構建的高性能服務,其核心工作流如圖所示,包含以下關鍵步驟:
步驟1:LLM辨證分析。 接收用戶症狀描述後,系統首先利用DeepSeek-Chat LLM進行中醫辨證,識別出1-3個最可能的證候。這壹步模擬了中醫師的辨證思維,爲後續精准推薦奠定基礎。
步驟2:證候知識檢索。 將識別出的證候重排序識別出主要證候,然後將識別出的主要證候編碼爲向量,在證候知識庫中檢索相關的中醫理論知識,包括該證候的臨床表現、治療原則、常用方藥等信息。
步驟3:反饋增強上下文構建。 系統利用BGE-M3對當前症狀進行編碼,並在PostgreSQL反饋庫中執行向量相似度搜索。它會聚合在語義相似症狀下獲得高評分(如≥8.0)的推薦項作爲正向偏好,同時也會識別出普遍低分(如≤3.0)的推薦項作爲負向警示,共同構成“用戶反饋參考”上下文。
步驟4:LLM推理與生成。 將證候知識摘要和反饋增強上下文壹並注入到DeepSeek-Chat LLM[24]的提示詞(Prompt)中。LLM根據這些結構化信息,遵循預設的辨證原則(如經典優先、安全第壹),最終輸出包含辨證分析、推薦理由和具體方藥詳情的自然語言回答。此過程嚴格約束了LLM的生成邊界,有效緩解了其固有的“幻覺”問題。
引擎層核心工作流
整體技術方案
完整覆蓋:從瓶頸→技術→數據→知識→AI→應用→價值的完整鏈條
三位壹體:大模型+RAG+向量反饋+LoRA微調的協同架構
知識全景:覆蓋"藥材-成分-靶點-通路-症候-制劑"全鏈條知識圖譜
技術融合:AI技術與細胞營養、生物發酵等生物技術深度整合
數據驅動:古籍典籍、現代文獻、專利數據、實驗數據的多源融合
價值量化:明確的周期縮短、成本降低、效率提升指標
反饋閉環:實驗驗證反饋驅動模型持續優化
整體技術方案